同济大学王昊奋 知识图谱在多模态大数据时代的创新与实践——世界人工智能大会达观数据论坛观点摘要
在近日举行的世界人工智能大会达观数据论坛上,同济大学特聘研究员、博士生导师王昊奋博士围绕“知识图谱在多模态大数据时代的创新和实践”这一主题,分享了前沿的学术洞察与行业实践经验。该论坛作为大会的重要组成部分,由达观数据联合CSDN等知名技术社区举办,聚焦人工智能基础软件的开发与应用,吸引了众多学术界与产业界的专家参与。
王昊奋博士首先指出,随着大数据技术的飞速发展,数据形态已从传统的结构化文本,演变为涵盖文本、图像、音频、视频等多种模态的复杂综合体。多模态大数据在带来丰富信息价值的也因其异构性、关联复杂和语义鸿沟等问题,对信息的深度理解与智能处理提出了巨大挑战。在这一背景下,知识图谱作为结构化语义知识库,成为连接多模态数据、实现认知智能的关键基础设施。
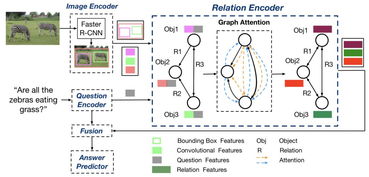
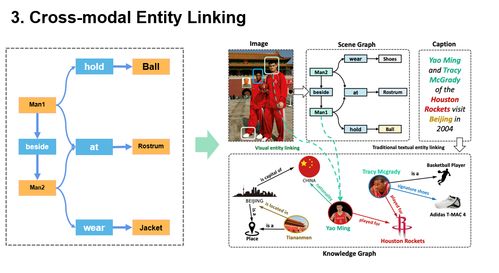
在创新层面,王昊奋重点介绍了其团队在多模态知识图谱构建与推理方面的最新探索。传统知识图谱主要基于文本构建,而多模态知识图谱的核心创新在于能够融合并关联不同模态数据中的实体与概念。例如,通过计算机视觉技术识别图像中的物体,通过自然语言处理技术理解描述文本,并将这些信息与知识图谱中的实体节点进行精准对齐和关联,从而构建起一个“可看、可听、可读”的立体化知识网络。这种融合不仅丰富了知识的表达维度,也为更高级的语义理解与跨模态检索、问答等应用奠定了基础。
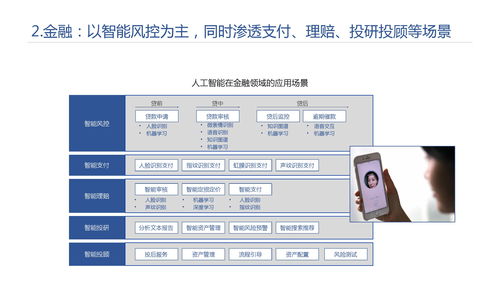
在实践应用方面,王昊奋结合达观数据等企业在人工智能基础软件开发中的实际案例,阐述了多模态知识图谱如何赋能产业。在智能金融领域,知识图谱可以整合公司年报、新闻舆情、股价图表等多源异构数据,构建产业链与风险关联网络,辅助进行投研分析与风险管控。在智慧医疗领域,通过关联医学文献、临床影像、病理报告和基因数据,可以构建疾病知识图谱,辅助医生进行诊断决策和科研发现。在智能内容审核与推荐领域,多模态知识图谱能够深入理解图文、视频内容的深层语义与上下文关联,实现更精准、更安全的审核与个性化推荐。
王昊奋强调,多模态知识图谱的落地离不开坚实的人工智能基础软件栈支撑。这包括高效的多模态数据预处理与特征提取工具、可扩展的知识存储与计算引擎、以及面向领域的可视化与交互开发平台。达观数据等企业在此领域持续投入,致力于开发低代码、高性能的知识图谱平台,降低技术应用门槛,推动知识图谱技术在更多行业场景中规模化落地。
王昊奋展望了未来趋势。他认为,多模态知识图谱将与大规模预训练模型(如多模态大模型)深度融合。知识图谱能为大模型提供结构化的先验知识,提升其推理的可解释性与准确性;而大模型强大的语义表示与生成能力,又能反过来助力知识图谱的自动化构建与动态演化。两者协同,将共同驱动下一代人工智能系统向更深层次的认知与决策智能迈进。
本次分享在CSDN等技术博客社区也引发了广泛讨论,为从事人工智能基础软件研发的工程师和研究人员提供了宝贵的思路与方向。知识图谱作为AI的“知识大脑”,正在多模态大数据时代扮演愈加核心的角色,其创新与实践将持续推动人工智能技术赋能千行百业。
如若转载,请注明出处:http://www.bxtsu.com/product/6.html
更新时间:2026-06-19 17:01:13